Summary
Diffuse Large B-Cell Lymphoma (DLBCL) is the most common non-Hodgkin lymphoma worldwide. DLBCL is fatal without treatment, but early detection and therapy can cure up to 70% of patients. The current best prognostic classification, the National Comprehensive Cancer Network International Prognostic Index, is insufficient to guide therapeutic decision-making for individual patients. No tumor-intrinsic prognostication method is currently available.
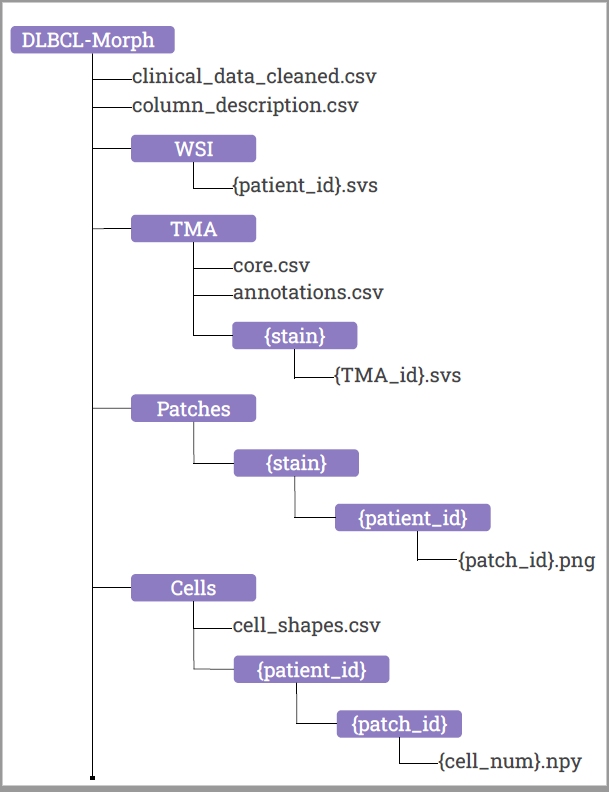
The DLBCL-Morph dataset contains 42 digital high-magnification scans of tissue microarrays (TMAs) containing tissue cores from 209 DLBCL cases at Stanford Hospital. Each DLBCL case is accompanied by survival data, follow-up status and a wide variety of clinical and cytogenetic variables. The TMAs are stained for H&E, which shows cell morphology, as well as for the expression of several prognostically relevant proteins: CD10, BCL6, MUM1, BCL2, and MYC. The TMAs are accompanied by pathologist-annotated regions of interest (ROIs) that specify areas of tissue representative of DLBCL. We used deep learning to segment out cancerous nuclei from the ROIs, and computed several geometric features for each cancerous nucleus, which are provided as part of our dataset. These geometric features quantify several morphologic properties of a nucleus, such as size and elongation, and can be used as input for automated prognostic models to predict survival. In addition, DLBCL-Morph contains 204 digital high-magnification whole-slide images (WSIs) from 149 DLBCL cases, stained for H&E.
A total of 152,194 patches (240x240 pixels each) were extracted from the H&E stained ROIs and a HoVer-Net model was used to segment tumor nuclei (1,035,909 binary masks). Geometric descriptors were computed for each segmented nucleus and a Cox proportional hazards model was evaluated using A) only clinical features, B) only morphologic features, or C) both sets of features. The Cox model achieved a concordance index of A) 0.703 (p = 0.005) B) 0.645 (p = 0.07), and C) 0.723 (p < 0.001) on a randomly sampled validation set of 51 patients. Our findings suggest that a risk calculator based on both clinical and morphologic data could yield improved prognostic value for DLBCL without the need for additional diagnostic testing.
Several studies have thus far failed to conclusively demonstrate that morphologic classification can predict outcomes in DLBCL. Automated medical imaging methods on whole slide images (WSI) could potentially identify novel, prognostically significant morphological or immunohistochemical biomarkers. The ability of automated methods to identify prognostically relevant features on H&E sections that have eluded pathologists has been demonstrated (Beck et al Science Translational Med). Furthermore, if successful, automated image analysis could potentially be scaled up into a cost-effective alternative to current classification methods which are typically costly and/or labor intensive. A critical requirement for the development of such deep learning models is the availability of datasets containing WSIs appropriately stained to show cell morphology and oncogene expression, with accompanying prognostic outcome data.
Data Access
| Data Type | Download all or Query/Filter | License |
|---|---|---|
| Tissue Slide Images (SVS, 350GB) | (Download and apply the IBM-Aspera-Connect plugin to your browser to retrieve this faspex package) | |
| Clinical data (CSV, 16 kB) | ||
| Clinical data column descriptions (CSV, 3 kB) |
Detailed Description
| Image Statistics | |
|---|---|
Modalities | Pathology |
Number of Patients | 209 |
Number of Images | 246 |
| Images Size (GB) | 350 |
Additional information about TM folder in dataset
Each row in the core.csv corresponds to a TMA core where ‘patient_id’ corresponds to the id of the patient the core belongs to. The columns ’tma_id’, ‘row’, and ‘col’ are used for locating the core in the TMA where ‘row’ and ‘col’ refers to the row and column location of the core in the TMA file with filename ’tma_id’.
In the annotations.csv file, the columns xs, ys, xe, & ye are coordinates (’s’ and ‘e’ abbreviated for ’start’ and ‘end’, respectively) where (xs, ys) and (xe, ye) is the xy-coordinates of the upper left corner and lower right corner of the annotation respectively.
Citations & Data Usage Policy
Users must abide by the TCIA Data Usage Policy and Restrictions. Attribution should include references to the following citations:
Data Citation
Fernandez-Pol, S., Natkunam, Y., Vrabac, D., Rojansky, R., Advani, R., Rajpurkar, P., S, & Ng, Andrew Y. (2022). H&E and immunohistochemical stain images of 209 cases of diffuse large B-cell lymphoma linked with cytogenetic features and clinical outcomes (Version 1) [Data set]. The Cancer Imaging Archive. https://doi.org/10.7937/NVA3-N783
TCIA Citation
Clark K, Vendt B, Smith K, Freymann J, Kirby J, Koppel P, Moore S, Phillips S, Maffitt D, Pringle M, Tarbox L, Prior F. The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository, Journal of Digital Imaging, Volume 26, Number 6, December, 2013, pp 1045-1057. DOI: 10.1007/s10278-013-9622-7
Other Publications Using This Data
TCIA maintains a list of publications which leverage TCIA data. If you have a manuscript you'd like to add please contact TCIA's Helpdesk.
Version 1 (Current): Updated 2022/03/25
| Data Type | Download all or Query/Filter |
|---|---|
| Images (SVS, 350GB) | |
| Clinical Data (CSV) |